FLOSS stands for Free 'Libre' Open Source Software. It is a term that is used to represent software that has very limited restrictions on its license. Users of FLOSS are given the right to read and alter its source code. It is important to remember that free software does not mean that the software is free of charge. It means that the software is free from restrictions. Think of it in terms of "free speech" rather than "free food". Of course, there's lots of software out there that can be both. Just imagine a world where you don't have to simply file a bug report on the software that you use and then wait for the manufacturers to get back to you (which could be a very long wait!). Perhaps, if you have the technical knowledge, you could add to the software or call upon others to try and improve it. This would benefit not just you but all other users of that piece of software. Folks used to call such software that is free of restrictions as FOSS without the 'L'. However, this caused some level of ambiguity since it led to the assumption that one did not have to pay for the software. Such a notion would have spelt doom for any business prospects that such software might have. Once the word 'Libre' (meaning Liberty in Spanish or French) was brought in, the meaning became clear. So what FLOSS can you get? Well, apart from your dentist, here's an extensive list compiled by Wikipedia. I'm not too much of an activist. So, I wouldn't tell you to get rid of your proprietary (possibly pirated?) software. You probably use free software anyway. If you use Firefox, VLC or Gimp, then you are already a part of the solution. There are other useful applications that you could use. All it takes is an open mind to make a difference.
Other important links:-
Free Software Foundation
Info on Free and Non-free Software Licenses
Making the Move
About Me
- Angelo
- I'm a colonist who has declared war on machines and intend to conquer them some day. You'll often find me deep in the trenches fighting off bugs and ugly defects in code. When I'm not tappity-tapping at my WMD (also, known as keyboard), you'll find me chatting with friends, reading comics or playing a PC game.
Wednesday, March 26, 2008
Monday, March 17, 2008
An introduction to the STL : Priority Queues
(Reader Level : Beginner)
(Knowledge assumptions : classes, std::vector, std::string, queues)
Hello all! This time we're going to look at another STL container - the Priority Queue. You probably know what a queue is but just in case you don't or your memory could use some jogging, here goes... A queue is a First In First Out data structure. It means that the first element you put into the queue is the first one to leave the queue. Think of it as one of those long queues at the supermarket. The sooner you enter the queue, the sooner you can leave. So what is a priority queue? A priority queue is a queue where elements are entered based on their priority. If the wife of the supermarket's Manager had to do some shopping, she might not have to wait in line(hypothetically speaking ;)). She could immediately walk to the front of the queue and check out her purchases. If the Manager's daughter were also present, then she would stand behind the wife because she doesn't get as much importance as the mother but is still more important than the rest of the frustrated patrons. I know, I know. Silly example but hopefully you get the idea. In order to illustrate the beauty of a priority queue let me describe a rather contrived problem. This question was presented to me for a programming competition held at my college university.
The Problem: Write a C++ program to accept a list of words from the user. The user must also enter a weight associated with each word. Finally, display the words in decreasing order of their weights.
Solution Attempt #1 : Using a vector:
The user having to enter words and associated weights is pretty basic stuff. So, I'm not going to write any of that code in order to keep this blog post as short as possible. Here's one possible way to do it with vectors.
Solution Attempt #2 : Using a priority queue:
We'll use the same class PrioritizedWord from above. That way my lazy self won't have to do much typing. :D
SGI Documentation on Priority Queues
Member functions of STL Priority Queue
SGI Documentation on sort algorithm
Enjoy!
(Knowledge assumptions : classes, std::vector, std::string, queues)
Hello all! This time we're going to look at another STL container - the Priority Queue. You probably know what a queue is but just in case you don't or your memory could use some jogging, here goes... A queue is a First In First Out data structure. It means that the first element you put into the queue is the first one to leave the queue. Think of it as one of those long queues at the supermarket. The sooner you enter the queue, the sooner you can leave. So what is a priority queue? A priority queue is a queue where elements are entered based on their priority. If the wife of the supermarket's Manager had to do some shopping, she might not have to wait in line(hypothetically speaking ;)). She could immediately walk to the front of the queue and check out her purchases. If the Manager's daughter were also present, then she would stand behind the wife because she doesn't get as much importance as the mother but is still more important than the rest of the frustrated patrons. I know, I know. Silly example but hopefully you get the idea. In order to illustrate the beauty of a priority queue let me describe a rather contrived problem. This question was presented to me for a programming competition held at my college university.
The Problem: Write a C++ program to accept a list of words from the user. The user must also enter a weight associated with each word. Finally, display the words in decreasing order of their weights.
Solution Attempt #1 : Using a vector:
The user having to enter words and associated weights is pretty basic stuff. So, I'm not going to write any of that code in order to keep this blog post as short as possible. Here's one possible way to do it with vectors.
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
//This class encapsulates a word that can be prioritized based on a number.
class PrioritizedWord
{
private:
std::string m_word;
int m_priority;
public:
explicit PrioritizedWord()
{}
explicit PrioritizedWord(const std::string& word, const int priority = 0) : m_word(word), m_priority(priority)
{}
//Compares two words. This overloaded operator prioritizes words according to their weight.
const bool operator <(const PrioritizedWord& pW) const
{
return (m_priority < pW.m_priority);
}
//Overloaded "put to" operator for streaming output.
friend std::ostream& operator <<(std::ostream& out, const PrioritizedWord& pW)
{
out<<pW.m_word;
return out;
}
};
int main()
{
std::vector<PrioritizedWord> vWords;
vWords.push_back(PrioritizedWord("Angelo", 23));
vWords.push_back(PrioritizedWord("This", -1));
vWords.push_back(PrioritizedWord("Here", 51));
vWords.push_back(PrioritizedWord("Was", -1));
std::sort(vWords.begin(), vWords.end());
for(std::vector<PrioritizedWord>::size_type i = 0; i < vWords.size(); ++i)
{
std::cout<<vWords[i];
}
return 0;
}Solution Attempt #2 : Using a priority queue:
We'll use the same class PrioritizedWord from above. That way my lazy self won't have to do much typing. :D
#include <iostream>
#include <string>
#include <queue> //Instead of vectors, we now use a queue.
//PrioritizedWord Class definition goes here.
int main()
{
std::priority_queue<PrioritizedWord> wordQueue;
wordQueue.push(PrioritizedWord("Angelo", 23));
wordQueue.push(PrioritizedWord("Here", 51));
wordQueue.push(PrioritizedWord("Was", -1));
//Peek and pop until the priority queue is empty.
while(!wordQueue.empty())
{
std::cout<<wordQueue.top()<<" ";
wordQueue.pop();
}
return 0;
}SGI Documentation on Priority Queues
Member functions of STL Priority Queue
SGI Documentation on sort algorithm
Enjoy!
Friday, March 14, 2008
More Free Stuff: Open Stickers
Recently, a friend of mine pointed me to a site that gave free sticker books. You can download them for free, print and use them wherever you like. The theme of the stickers was Open Source. I'm a big supporter of the Open Source philosophy (more on that later). I decided to give my laptop a makeover. Here's what I ended up with:







You can get these cool stickers too!







You can get these cool stickers too!
Sunday, March 9, 2008
Free Stuff - Code::Blocks new release
Interested? Hop on over and give it a try.
Code::Blocks 8.02 Free C++ IDE
 Screenshot1: Building and executing a simple SDL application with Code::Blocks 8.02
Screenshot1: Building and executing a simple SDL application with Code::Blocks 8.02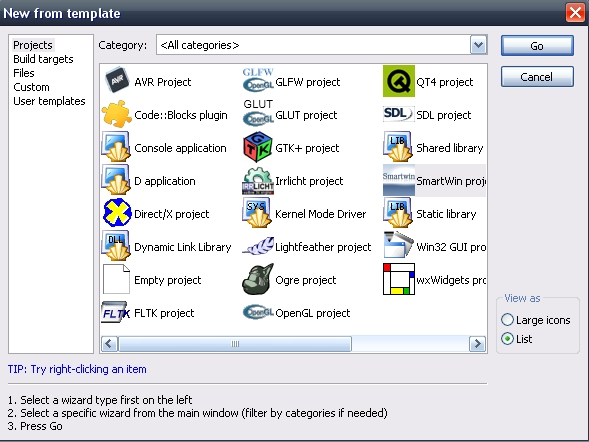 Screenshot2: An amazing number of project templates for developers from all walks of life.
Screenshot2: An amazing number of project templates for developers from all walks of life. Screenshot3: Programming doesn't have to be stressful with the BYO Games tetris plugin. There's one for snake as well.
Screenshot3: Programming doesn't have to be stressful with the BYO Games tetris plugin. There's one for snake as well.Saturday, March 8, 2008
An introduction to the STL : Maps
(Reader Level : Beginner)
(Knowledge assumptions : std::string, std::vector)
Hello! Today we're going to discuss another popular data structure in the STL - Maps. Maps are basically associative arrays or hash tables where each element consists of a unique key that identifies a particular value. Once a key is stored in the map, then it cannot be changed. Only the value it identifies can be changed. If we want to associate a new key with a value, then the entire element(key + value) must be removed from the map and the new element inserted. To actually see the beauty of maps, let us attempt to solve a simple problem.
The Problem: Write a C++ program to find the character with most number of occurrences in a string.
Solution attempt #1 : Using Vectors
This solution, of course, works but it has some pretty serious drawbacks. The first shortcoming is that it only works with lowercase strings. If the string were to contain uppercase characters or other special characters like spaces, then the solution fails. We could resize the vector to account for all 256 ASCII characters (or maybe all UNICODE characters) but then that would be wasted space if only a handful of characters were actually present in the string. Also, as we will soon see, this problem could have been solved more elegantly. I especially hate that part where we determined the index of the character in the vector.
Now, on to maps. If we analyse the problem more closely, we will come to the conclusion that what we really want to do is maintain a count of the number of occurrences for each character in the string. In other words, each unique character in the string is associated with a count. This concept could best be represented with a map where each element consists of a character as the key and an integer as the value. Let's try doing that.
Solution attempt #2 : Using Maps
There's more to maps than meets the eye. For more information on maps, feel free to read up on the following links:
SGI Documentation on Maps
Member functions of STL Map
In my next post, I'll talk about another STL container - The Priority Queue.
(Knowledge assumptions : std::string, std::vector)
Hello! Today we're going to discuss another popular data structure in the STL - Maps. Maps are basically associative arrays or hash tables where each element consists of a unique key that identifies a particular value. Once a key is stored in the map, then it cannot be changed. Only the value it identifies can be changed. If we want to associate a new key with a value, then the entire element(key + value) must be removed from the map and the new element inserted. To actually see the beauty of maps, let us attempt to solve a simple problem.
The Problem: Write a C++ program to find the character with most number of occurrences in a string.
Solution attempt #1 : Using Vectors
#include <iostream>
#include <string>
#include <vector>
const char VectorMethodOfCounting(const std::string& str)
{
std::vector<unsigned int> vCharCount(26);
char mostUsedChar = '\0';
unsigned int count = 0, currentIndex;
for(std::string::size_type i = 0; i < str.length(); ++i)
{
//Calculate the index of this character in the vector.
currentIndex = str[i] - 'a';
++vCharCount[currentIndex];
if(vCharCount[currentIndex] > count)
{
mostUsedChar = str[i];
count = vCharCount[currentIndex];
}
}
return mostUsedChar;
}
int main()
{
std::string myString = "thebrowncowjumpedoverthemoon";
std::cout<<VectorMethodOfCounting(myString);
return 0;
}This solution, of course, works but it has some pretty serious drawbacks. The first shortcoming is that it only works with lowercase strings. If the string were to contain uppercase characters or other special characters like spaces, then the solution fails. We could resize the vector to account for all 256 ASCII characters (or maybe all UNICODE characters) but then that would be wasted space if only a handful of characters were actually present in the string. Also, as we will soon see, this problem could have been solved more elegantly. I especially hate that part where we determined the index of the character in the vector.
Now, on to maps. If we analyse the problem more closely, we will come to the conclusion that what we really want to do is maintain a count of the number of occurrences for each character in the string. In other words, each unique character in the string is associated with a count. This concept could best be represented with a map where each element consists of a character as the key and an integer as the value. Let's try doing that.
Solution attempt #2 : Using Maps
#include <iostream>
#include <string>
#include <map>
const char MapMethodOfCounting(const std::string& str)
{
std::map<char, unsigned int> mapCharCount;
char mostUsedChar = '\0';
unsigned int count = 0;
for(std::string::size_type i = 0; i < str.length(); ++i)
{
++mapCharCount[str[i]];
if(mapCharCount[str[i]] > count)
{
mostUsedChar = str[i];
count = mapCharCount[str[i]];
}
}
return mostUsedChar;
}
int main()
{
std::string myString = "thebrowncowjumpedoverthemoon";
std::cout<<MapMethodOfCounting(myString);
return 0;
}There's more to maps than meets the eye. For more information on maps, feel free to read up on the following links:
SGI Documentation on Maps
Member functions of STL Map
In my next post, I'll talk about another STL container - The Priority Queue.
Monday, March 3, 2008
An introduction to the STL : Vectors
(Reader Level : Beginner)
(Knowledge assumptions : Arrays)
Today I'm going to cover a pretty basic standard library provision that I feel every C++ programmer should know about - Standard Template Library Vectors. Vectors (don't mind the wierd sounding name) are similar to C-style arrays but with more safety. Whenever I explain a concept, I prefer to illustrate what I mean with some code. Let's first try to create a one-dimensional C-style array of type int:
One of the biggest drawbacks of C-style arrays is that the dimension(s) of an array must be known at the time of declaration. This generally leads to wastage of allocated space. In our example, we can't add more than 3 integers to the array because we've already decided on its maximum size at compile time.
Another shortcoming of arrays is that its very easy to trip up and access beyond the bounds of an array. In our example, we inadvertently tried to print the value of myArray[3] simply because its quite hard to remember a hard-coded dimension. Of course, there's lots of other ways by which an out-of-bounds access can happen but we'll just stick to the basics for the time being.
Alright then, let's rewrite the exact same code as above, only this time we'll use Vectors.
At the top we include the pre-compiled header file for using vectors. In main(), we declare a vector of integers called myVector. By default, the initial size of myVector will be zero which means that there is no memory allocated for it. Note that, vectors are also named within the std namespace just as cout is. After we declare the vector, we then add data to this vector using a function named push_back(). Since this is an integer vector, we push integers into the vector. This means that at the end of the three pushes, our vector will be as follows:
myVector[0] = 10;
myVector[1] = 20;
myVector[2] = 30;
However, we couldn't just substitute these statements in place of the three push_back() function calls. Why? Remember that the size of myVector was zero when we declared it. So, trying to access an element of the vector through an index will lead to an out-of-bounds access. Finally, we iterate through all the elements in the vector and display the value of each element. The function size() gives us the number of elements in the vector. So, there's no way we could iterate beyond the bounds of the vector. Now you may ask, what's with that wierd data type with which the variable 'i' was declared? It's nothing but a defined type that is implementation specific for vectors. Since we are iterating over the elements of the vector based on its size, the maximum value of the variable i can be the maximum size for any vector.
There are lots of other cool things one could easily do with vectors. For example, you could resize a vector(doing that with an array would be a major headache) or clear the contents of the vector in one go. Unfortunately, all those cool things are beyond the scope of this measly blog post. The following links should help you get started on STL Vectors:
A Beginner's Tutorial For std::vector, Part 1
Member functions of STL Vector
In my next post, I hope to introduce you to another useful STL container.
(Knowledge assumptions : Arrays)
Today I'm going to cover a pretty basic standard library provision that I feel every C++ programmer should know about - Standard Template Library Vectors. Vectors (don't mind the wierd sounding name) are similar to C-style arrays but with more safety. Whenever I explain a concept, I prefer to illustrate what I mean with some code. Let's first try to create a one-dimensional C-style array of type int:
#include <iostream>
int main()
{
int myArray[3];
myArray[0] = 10;
myArray[1] = 20;
myArray[2] = 30;
//myArray[3] = 40; //Can't add any more.
for(int i = 0; i < 4; ++i) //Out of bounds!
{
std::cout<<myArray[i]<<std::endl;
}
return 0;
}One of the biggest drawbacks of C-style arrays is that the dimension(s) of an array must be known at the time of declaration. This generally leads to wastage of allocated space. In our example, we can't add more than 3 integers to the array because we've already decided on its maximum size at compile time.
Another shortcoming of arrays is that its very easy to trip up and access beyond the bounds of an array. In our example, we inadvertently tried to print the value of myArray[3] simply because its quite hard to remember a hard-coded dimension. Of course, there's lots of other ways by which an out-of-bounds access can happen but we'll just stick to the basics for the time being.
Alright then, let's rewrite the exact same code as above, only this time we'll use Vectors.
#include <iostream>
#include <vector>
int main()
{
std::vector<int> myVector;
myVector.push_back(10);
myVector.push_back(20);
myVector.push_back(30); //Add some more if you like. :)
for(std::vector<int>::size_type i = 0; i < myVector.size(); ++i) //Safer...
{
std::cout<<myVector[i];
}
return 0;
}
At the top we include the pre-compiled header file for using vectors. In main(), we declare a vector of integers called myVector. By default, the initial size of myVector will be zero which means that there is no memory allocated for it. Note that, vectors are also named within the std namespace just as cout is. After we declare the vector, we then add data to this vector using a function named push_back(). Since this is an integer vector, we push integers into the vector. This means that at the end of the three pushes, our vector will be as follows:
myVector[0] = 10;
myVector[1] = 20;
myVector[2] = 30;
However, we couldn't just substitute these statements in place of the three push_back() function calls. Why? Remember that the size of myVector was zero when we declared it. So, trying to access an element of the vector through an index will lead to an out-of-bounds access. Finally, we iterate through all the elements in the vector and display the value of each element. The function size() gives us the number of elements in the vector. So, there's no way we could iterate beyond the bounds of the vector. Now you may ask, what's with that wierd data type with which the variable 'i' was declared? It's nothing but a defined type that is implementation specific for vectors. Since we are iterating over the elements of the vector based on its size, the maximum value of the variable i can be the maximum size for any vector.
There are lots of other cool things one could easily do with vectors. For example, you could resize a vector(doing that with an array would be a major headache) or clear the contents of the vector in one go. Unfortunately, all those cool things are beyond the scope of this measly blog post. The following links should help you get started on STL Vectors:
A Beginner's Tutorial For std::vector, Part 1
Member functions of STL Vector
In my next post, I hope to introduce you to another useful STL container.
Subscribe to:
Posts (Atom)